La caída Amazon AWS comenzó alrededor de las 11:48 p. m. del 19 de octubre, debido a un fallo en DNS que afectó servicios críticos como DynamoDB (servicio de base de datos noSQL), EC2 (Elastic Compute Cloud, es un servidor virtual en la nube AWS) e IAM (Identity and Access Management, es un servicio de control de acceso a los recursos de AWS) en la región US‑EAST‑1 —Virginia del Norte—
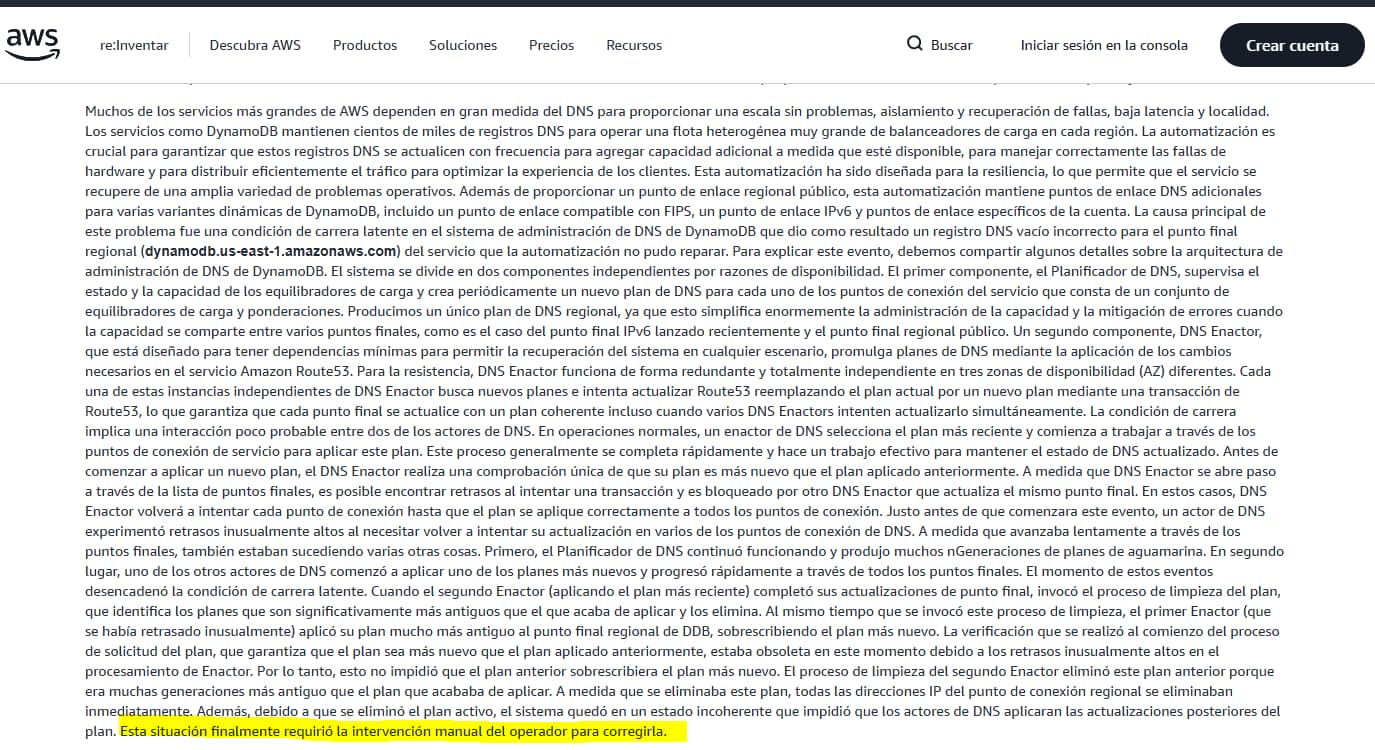
AWS afirmó que había un error en su software de automatización que provocó una serie de problemas en cadena. La compañía explicó que se debía a «un defecto latente en el sistema automatizado de gestión de DNS [sistema de nombres de dominio] del servicio».
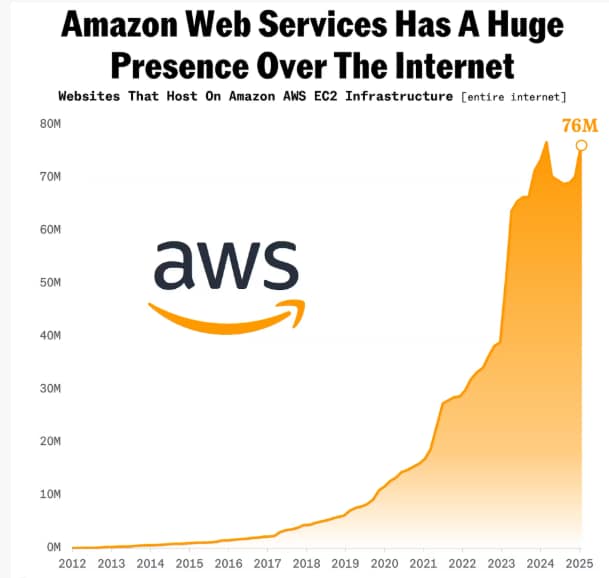
Amazon es el principal proveedor de servicios en la nube a nivel global, negocio que genera el 53% de sus ingresos operativos. Se estima que cerca de 76 millones de sitios web están construidos con AWS, entre ellos 36% de las páginas más visitadas en el mundo.
El incidente afecto millones de dispositivos y plataformas digitales quedando fuera de servicio al mismo tiempo. Los timbres y cámaras Ring (propiedad de Amazon) dejaron de enviar alertas. Las camas inteligentes Eight Sleep no pudieron regular la temperatura ni registrar el sueño de sus usuarios. Parlantes, luces y otros dispositivos conectados quedaron mudos. Lo que parecía un problema técnico remoto terminó afectando rutinas cotidianas y exponiendo una fragilidad profunda: la dependencia casi total de la conectividad.
Alcance del impacto AWS
- La interrupción provoco fallas en más de 3,500 empresas en más de 60 países.
- Se generaron más de 17 millones de reportes de fallo de usuarios a lo largo del evento. [ookla.com]
- Se estiman pérdidas cercanas a $75 millones de dólares por cada hora de inactividad en las plataformas críticas, siendo aproximadamente $72 millones el costo directo para AWS.
- Por ejemplo, Amazon.com podría haber perdido $73 millones por hora, mientras que plataformas como Snapchat y Zoom podrían haber sufrido entre $0.5 y $0.6 millones por hora. [economicti…atimes.com]
- Según Mehdi Daoudi, CEO de Catchpoint, las consecuencias económicas del incidente podrían llegar a miles de millones de dólares, incluso a cientos de miles de millones, debido a la paralización de operaciones y la pérdida de productividad global. [livemint.com], [forbes.com]
Lista de empresas afectadas por caída AWS
Empresas afectadas a nivel global
La siguiente lista representa solo la parte más destacada del impacto global; se reportaron afectaciones en más de 3,500 empresas y servicios en diversos sectores:
🎮 Gaming
- Fortnite – Epic Games
- Roblox
- Rainbow Six Siege
- PUBG Battlegrounds
- Rocket League
📱 Apps sociales, mensajería y entretenimiento
- Snapchat
- Discord
- Signal
- Wordle
- Whatnot
- Twitch
- Character.AI
- Perplexity AI
- OpenAI
- Claude (Anthropic)
🎬 Streaming / Medios / Video
- Netflix (según antecedentes)
- Prime Video
- Crunchyroll
- HBO Max
- Disney+
- Roku
- FuboTV
- YouTube
- Spotify
- Apple TV
- Vimeo
- NPM (package manager)
💰 Finanzas / Pagos / Banca
- Robinhood
- Coinbase
- Venmo
- Chime
- Navy Federal Credit Union
- Barclays
- Bank of Scotland
- Lloyds Bank
🛒 E‑commerce / Retail
- Amazon.com
- Shopify
- Etsy
- DoorDash
- McDonald’s (app)
🏢 Productividad / Herramientas de negocio
- Slack
- Microsoft Teams / Office 365
- Zoom
- MyFitnessPal
- Trello
- Mailchimp
- Box
- Asana
- Smartsheet
- Fanduel
- HighLevel (Marketing)
- Dialpad
- Cursor (AI code editor)
- Google Drive / Gmail / Google Meet
- reCAPTCHA
- Google Cloud
- Microsoft Azure (por dependencias cruzadas)
- Canvas by Instructure
- CollegeBoard
- Khan Academy
- Life360
🏡 IoT / Smart Home
- Alexa
- Ring
- Google Nest
🚗 Transporte / Viajes
- Lyft
- Delta Air Lines
- United Airlines
📡 Infraestructura TI / Tecnología
- Cloudflare
- Google Maps
- AT&T
- Verizon
- Google (search)
Fuentes principales
- Dataconomy (lista extensa y categorizada) [dataconomy.com]
- Tom’s Guide (detalle de servicios financieros, juegos, mensajería y otros) [tomsguide.com]
Empresas afectadas en Colombia
En Colombia, el incidente de AWS afectó principalmente los servicios digitales de banca y fintech, impactando al menos siete entidades financieras.
Listado de empresas y servicios en Colombia que se vieron afectados:
| Sector | Empresas / Servicios colombianos afectados | Detalles |
|---|---|---|
| Banca y fintech | Bancolombia, Nequi, Davivienda, Daviplata, Colpatria, Banco Caja Social, Nu, Banco de Bogotá, Ualá | Interrupciones en canales digitales: apps móviles, transferencias, consultas de saldo [infobae.com], [ifmnoticias.com] |
| Banca presencial | Cajeros automáticos y corresponsales | Continuaron operativos pese a la caída digital [ifmnoticias.com], |
| Comercio electrónico y telecomunicaciones | Usuarios reportaron fallas en plataformas de retail y pagos digitales (PSE y código QR vinculados a Nequi y Davivienda) Claro, Movistar, Tigo. | Afectación detallada en fallas de carga y pago [ifmnoticias.com], |
Recomendaciones para el SGSI tras el incidente AWS
| Área SGSI | Recomendación |
|---|---|
| Gestión de riesgos | Actualizar el análisis de riesgos incluyendo la dependencia de servicios cloud como AWS. |
| Continuidad del negocio | Revisar y fortalecer los planes de continuidad y recuperación ante desastres (BCP/DRP). |
| Proveedor de servicios | Evaluar acuerdos de nivel de servicio (SLA) con AWS y considerar alternativas o redundancias. |
| Monitoreo y alertas | Implementar sistemas de monitoreo que detecten caídas en servicios críticos en tiempo real. |
| Comunicación de incidentes | Establecer protocolos claros para comunicar incidentes a usuarios internos y externos. |
| Capacitación | Sensibilizar al personal sobre el impacto de interrupciones en servicios cloud y cómo responder. |
| Auditoría y revisión | Realizar auditorías periódicas sobre la dependencia tecnológica de terceros. |
| Seguridad de la información | Verificar que los datos alojados en la nube tengan respaldos seguros y accesibles localmente. |
Posible causa del impacto en AWS
Unos meses atrás, en Julio, Amazon tomó la drástica decisión de recortar cientos de puestos de trabajo en la unidad de computación en la nube de AWS, según publicaron en Reuters. En octubre de 2025, Amazon anunció el recorte de 14.000 puestos corporativos en diversas áreas, incluyendo algunos dentro de AWS, con la justificación de eficiencia impulsada por IA.
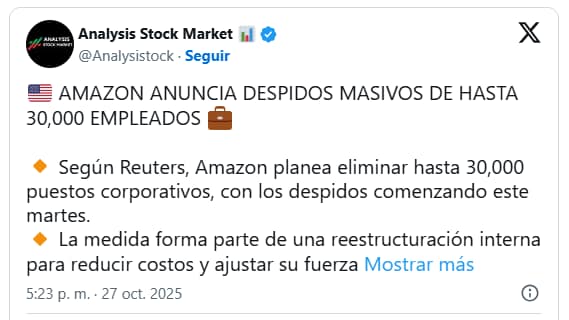
Esto significa que despidieron a trabajadores directamente implicados en el mantenimiento de esta infraestructura y como ha reconocido Amazon, «el error no se reparó automáticamente y requirió la intervención manual del operador«.
Tras el incidente en octubre de 2025, expertos y medios como Cybernews señalaron que las reiteradas salidas de ingenieros senior podrían haber debilitado la capacidad de AWS para prevenir y mitigar fallos como el de DNS. [cybernews.com] Según Futurism y otros medios, la reciente ola de despidos, incluyendo roles técnicos, coincidió con una mayor susceptibilidad frente a errores críticos en AWS.
Es razonable considerar que la presencia y acción de personas capacitadas podrían haber prevenido la ocurrencia del fallo o, en caso de que este ya se hubiera manifestado, haberlo solucionado de manera más eficiente y en un menor lapso de tiempo. La capacidad de análisis, la toma de decisiones y la aplicación de medidas correctivas por parte de individuos con el conocimiento adecuado probablemente habrían permitido una resolución más ágil y efectiva en comparación con la respuesta automática o la falta de intervención. En otras palabras, es muy posible que la gestión humana del problema hubiera conducido a un desenlace más favorable y expedito.
Reflexiones finales
Muchas empresas están utilizando cada vez más la IA para escribir código para su software y están adoptando agentes de IA para automatizar tareas rutinarias, con el fin de ahorrar costes y reducir la dependencia del personal, pero fallos como este, sobre todo a nivel mundial, siguen demostrando que el valor humano sigue siendo indispensable.
El apagón global de AWS fue una advertencia sobre los límites de la automatización y los riesgos de delegar funciones básicas a sistemas externos. La primera consecuencia es la falsa sensación de control. Creemos tener el manejo total del entorno porque todo está conectado, pero basta una falla para perderlo todo. Realizar pruebas periódicas de DR (Disaster Recovery), simulaciones de fallos y test de seguridad pueden garantizar que los planes funcionen en condiciones reales. También resulta clave diversificar proveedores y plataformas. Si todo el ecosistema depende de una sola empresa, una interrupción puede paralizarlo.
Con este incidente, surgen preguntas claves que debemos plantearnos: ¿Realmente somos tan resilientes como creemos?, ¿Conocemos nuestras dependencias externas? y ¿Hemos realizado todas las pruebas?

Recibe un Diagnóstico Sin Costo del estado de seguridad de tu aplicación o sitio web dando clic en el siguiente enlace: